For Early Access to Kling VIDEO 3.0, Join Kling as Pro, Premier, and Ultra.
The digital landscape witnesses a massive shift as professional video creation moves into a new era. High-quality visuals now meet native sound and complex storytelling through advanced artificial intelligence. Such a leap allows creators to handle cinematic tasks with unprecedented ease. Modern technology redefines the relationship between a director and creative software.
The Unified Training Framework of Kling VIDEO 3.0
The foundation of the Kling VIDEO 3.0 model series rests upon a deeply unified training framework. That architecture represents a significant departure from older methods, where visual and audio elements were handled as separate modules. Through the integration of multiple tasks into a single engine, the system achieves truly native multimodal output. Creators no longer deal with fragmented clips that lack coherence. Instead, the unified engine within Kling VIDEO 3.0 processes text, images, and audio as a single stream of information.
That technical breakthrough allows for a more fluid interaction between different creative modes. Whether the input is text or a reference image, the model treats every piece of data as part of a whole. Such a system forms the basis for a philosophy where all tools work in total harmony. The result is a more responsive and dynamic generation process where characters, backgrounds, and sounds exist in a state of natural balance. The leap from previous versions to the Kling VIDEO 3.0 era focuses on narrative depth and structural control, allowing a solitary creator to take on the role of a director with confidence.
Building on the successes of earlier models, the current engine integrates various complex tasks. These include text-to-video, image-to-video, and reference-to-video capabilities. The Kling VIDEO 3.0 model also handles video modification and transformation within the same unified training model. Through such integration, the platform reaches a standard of image realism and semantic accuracy that meets professional requirements. The synergy between text and visuals is now tighter, resulting in a system that grasps the subtle nuances of human language and artistic style. Every frame generated through Kling VIDEO 3.0 reflects a deep understanding of the intended scene.
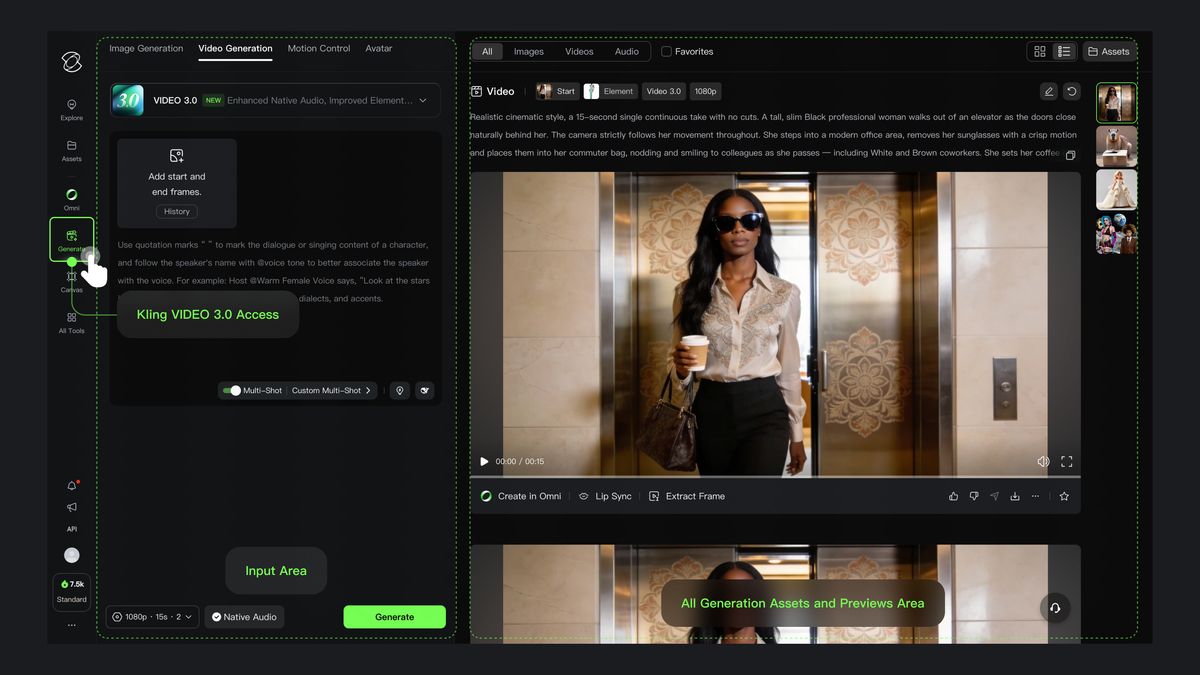
Multi-Shot: The Arrival of the AI Director
One of the most impressive additions in the Kling VIDEO 3.0 era is the Multi-Shot feature. That functionality serves as a built-in AI Director that understands the nuances of cinematic language. Previously, creating a scene with multiple camera angles required a long and tedious editing process. The current Kling VIDEO 3.0 model simplifies that task through one-click cinematic output. The system understands various shot types and coverage, allowing for complex narrative structures.
Cinematic Language and Automatic Composition
The Kling VIDEO 3.0 model possesses a deep understanding of cinematic languages. It can handle classic shot-reverse-shot dialogues with precision. If a creator wants a scene involving cross-cutting or complex transitions, the engine handles those adjustments automatically. That capability implies the system adjusts camera angles and compositions to match the narrative intent of the prompt. Such precision allows for the generation of a complete cinematic sequence in a single go, avoiding the need for manual cutting and external assembly.
Advanced Camera Control and Transitions
Creators can specify various camera movements within Kling VIDEO 3.0, such as horizontal tracking, low-angle stabilizer movements near the ground, or wide aerial views. The AI Director understands these instructions and applies them across multiple shots while maintaining the logic of the scene. Through those features, complex audiovisual expressions become accessible to all creators, regardless of their technical background in film editing. The system effectively takes over the role of an editor, crafting a story with natural transitions and professional framing. The fluidity of movement in Kling VIDEO 3.0 sets a new benchmark for automated cinematography.
| Prompt | Image | Outputs |
|---|---|---|
|
A middle-aged man is ordering food in a Western restaurant. He speaks in English with an Indian accent and says," Excuse me, I would like to order a seafood pasta, and a filet mignon. medium-rare." Then he looks up and continues:" And, do you have any drink recommendations?"
|

|
 |
Native Audio: Breaking the Barrier of Silence
The transition to Kling VIDEO 3.0 brings the end of silent visuals. The model generates visuals, voices, and sound effects simultaneously in a single pass. That native audio infusion adds a layer of realism and life to every clip. The integration of sound is not an afterthought; it is a core part of the generative process. Such a synchronized workflow provides a stronger sense of coherence and life to AI-generated visuals. Within the Kling VIDEO 3.0 environment, audio and video are born together, securing a perfect match in rhythm and atmosphere.
Multi-Language Support and Vocal Continuity
The Kling VIDEO 3.0 model also introduces upgraded native audio output with character referencing. That feature allows a character to maintain a consistent voice across different scenes. Beyond simple sound generation, the platform now supports a wide range of languages. These include Chinese, English, Japanese, Korean, and Spanish. The system provides authentic renditions of regional dialects and accents, which adds a layer of cultural depth to the storytelling.
Characters can even engage in multilingual dialogues within the same scene. Through those features, Kling VIDEO 3.0 caters to a global audience, allowing for more diverse and accurate narratives. The inclusion of native audio means that the final output requires far less post-production work, as the sound and image are already perfectly aligned from the moment of generation. The Kling VIDEO 3.0 model extracts the essence of a voice and applies it to the visual performance, creating a unified sensory experience that feels grounded in reality. The ability to bind voices to characters provides a level of continuity that was previously difficult to achieve.
| Prompt | Image | Outputs |
|---|---|---|
|
Home setting with a faint hum of the living room air conditioner in the background for a
realistic daily vibe. Mom (softly, in a surprised tone): Wow, I didn't expect this plot at all.
Dad (in a low voice, agreeing, in a calm tone): Yeah, it's totally unexpected. Never thought
that would happen. Boy (in an excited tone): It's the best twist ever! Gin (nodding along, in an
enthusiastic tone): I can't believe they did that!
|

|
|
Subject Consistency: Core Elements Locked In
Maintaining a consistent look for characters and items is a vital part of filmmaking. Kling VIDEO 3.0 introduces enhanced subject consistency specifically for image-to-video tasks. The model locks in core elements to guarantee that the traits of characters and items remain stable throughout the video. Regardless of camera movement or scene development, the key subjects remain recognizable and coherent.
Such stability allows creators to build persistent worlds where characters do not shift in appearance from frame to frame. The system anchors the visual identity of a subject, allowing the camera to move dramatically while keeping the focus on the established traits. That level of control is essential for narrative work where character recognition is paramount. Through anchoring these traits, the Kling VIDEO 3.0 model reaches a standard of consistency required for industrial-grade content.
The model leverages deep multimodal understanding to treat all inputs鈥攊ncluding reference images and text鈥攁s a unified prompt. That approach results in a significant improvement in element consistency compared to older models. The result is a more mature and usable work where every frame adheres to the visual standards set by the creator. Even in complex scenes with multiple moving parts, the primary subject remains the same, securing the narrative integrity of the piece. Kling VIDEO 3.0 maintains that stability through advanced reasoning algorithms that track every pixel of the subject.
15-Second Generation and Narrative Flow
The Kling VIDEO 3.0 model breaks through previous duration limits, allowing for continuous generations up to 15 seconds. While older versions were limited to shorter bursts, the current 15-second window provides enough space for complex action sequences. Creators can choose a flexible duration between 3 and 15 seconds, depending on the needs of the scene.
That extra time is crucial for unfolding a long shot or showing the progression of multiple plotlines. Instead of a series of short, disconnected moments, the 15-second generation through Kling VIDEO 3.0 allows for a story with a real sense of flow and progression. It gives the narrative the room it needs to breathe, allowing for subtle character reactions or the gradual build-up of tension within a single work.
The ability to generate longer clips without losing quality or consistency is a major technical achievement. It allows creators to present complex action sequences and scene developments in their entirety. Through those longer outputs, the platform expands the creative boundaries of AI-powered video creation, turning a textual description into a fluid narrative. One no longer needs to worry about fragmented assembly, as a story with real progression can now be fully presented within a single generation of Kling VIDEO 3.0. That extension of time opens doors for professional storytellers who require more than just a brief snippet.
| Prompt | Image | Outputs |
|---|---|---|
|
Opening with an ultra-wide angle medium-long shot tracking horizontally, the stabilizer moves
low to the ground, with a highly contrasting romantic cinematic tone of cold blue night and
silvery white starry sky, exuding a strong poetic realism and classical epic temperament. The
protagonist is a young woman in a dark green long dress, running with all her might on the
garden lawn illuminated by moonlight, her skirt billows in the wind forming surging dynamic
curves, she clutches a small white flower in her right hand, and lifts the hem of her dress with
her left, breathing rapidly yet with a firm gaze. At the 4th second, the camera accelerates
forward with her, and multiple men and women in old-era ball gowns break into the frame one
after another from the left and right sides in the background, running alongside her, some try
to approach, some turn back to shout, yet none truly touch her, implying pursuit and escape. At
the 8th second, the camera gradually zooms in to a medium shot, pans to track forward in front
of the protagonist, and lifts slightly. She glances back briefly at a young male character
behind her, their gazes meet for a split second, emotions erupt mid-run, and the woman and man
join hands to run together. At the 12th second, the music and movement reach a climax, the
camera moves forward close to her side face and fluttering hair, she releases the white flower
and tosses it into the air, the flower drifting down in slow motion as the crowd behind brushes
past it.In the final 3 seconds, the camera keeps moving forward, the woman and man break through
the crowd and dash toward the starry sky at the end of the garden, their figures gradually
taking over the center of the frame. The overall atmosphere is fiery, romantic, and resolute, a
burst of narrative about fate, choice, and freedom
|

|
 |
Precise Lettering and Visual Realism
A common struggle for AI video models involves the accurate rendering of text. Kling VIDEO 3.0 addresses that challenge through native-level text output. The model features precise lettering capabilities, allowing for clear and accurate words to appear within the generated video. Whether it is a sign on a storefront, a neon billboard in a futuristic city, or words on a document, the system renders characters with high fidelity.
That precision is a result of improved semantic response accuracy. The Kling VIDEO 3.0 model interprets the intentions of the user more effectively, leading to fewer visual distortions. The overall realism of the images is significantly higher, with characters performing in a more expressive and dynamic manner. Movement feels more natural, and the visual quality meets the high standards of the digital media industry.
The model even handles complex artistic prompts with ease. For example, a prompt describing a high-contrast romantic cinematic color grading with a cold blue night and silvery starry sky can be rendered with poetic realism. The movement of the characters and the environment remains fluid and natural, creating a professional look that was previously difficult to achieve without extensive manual work. Kling VIDEO 3.0 captures the fine details of hair, skin texture, and environmental lighting, rendering scenes that are visually stunning and emotionally resonant. Every generation through Kling VIDEO 3.0 showcases a level of detail that rivals traditional cinematography.
Comparison of Model Capabilities: 2.6 vs 3.0
The leap from the previous version to the Kling VIDEO 3.0 model series is clear when looking at the core capabilities. The following table, reflecting the latest official data from technical screenshots, clarifies the professional advantages of the new generation.
|
Capabilities |
Kling VIDEO 2.6 |
Kling VIDEO 3.0 |
|
Text-to-Video |
Supported |
Supported |
|
Image-to-Video |
Supported |
Supported |
|
Start & End Frames-to-Video |
Supported |
Supported |
|
Native Audio |
Supported |
Supported |
|
Multi-Shot |
Not Supported |
Supported |
|
Start Frame + Element Reference |
Not Supported |
Supported |
|
Multi-Character Coreference (3+) |
Not Supported |
Supported |
|
Multilingual Support (CN, EN, JP, KR, SP) |
Not Supported |
Supported |
|
Dialects and Accents |
Not Supported |
Supported |
|
15s Output Duration |
Not Supported |
Supported |
|
Flexible Duration |
Not Supported |
Supported |
Through those advancements, Kling VIDEO 3.0 provides a toolset that caters to both hobbyists and professional filmmakers. The ability to handle complex shots and maintain consistency without external editing is a major shift in the field. The platform handles the complexity, allowing the user to act as the creative visionary.
A Practical Workflow for Modern Directors
Using Kling VIDEO 3.0 allows for a more streamlined creative process. A typical workflow might begin with a reference image to establish the look of a character or a scene. Through the use of enhanced subject consistency, the creator guarantees that the visual identity remains stable throughout the generation. That character can then be used in various shots while maintaining the same traits.
With the subject established, the creator can use the Multi-Shot prompting system within Kling VIDEO 3.0 to describe a narrative sequence. The user might specify distinct shots within a 15-second generation, such as a wide shot of a character entering a room, followed by a close-up of their reaction. The AI Director handles the transitions, camera angles, and ambient sound automatically. Using these tools, a creator can focus on the artistic vision rather than the technical hurdles.
The combination of native audio and element consistency means the final output requires minimal editing. Such a process makes complex expressions accessible to all types of creators. The power to turn a textual description into a cinematic reality is now within reach for everyone. Through those tools, the era of solo filmmaking becomes a practical reality. Every user now possesses the ability to produce high-quality work with a single click in Kling VIDEO 3.0.
Future Outlook of the Kling VIDEO 3.0 Era
The launch of Kling VIDEO 3.0 redefines the boundaries of AI storytelling. As the tools for consistency, audio, and cinematic control become more accessible, the barriers to entry continue to fall. The platform continues to evolve, with the unification of tasks into a single training model suggesting a future where AI can handle even more complex narrative structures.
Through the ongoing enhancement of realism and semantic accuracy, the gap between AI-generated content and traditional cinema continues to shrink. Kling VIDEO 3.0 serves as a powerful engine for creativity, providing the necessary tools to build scenes with depth, sound, and emotional resonance. It is not just an update; it is a fundamental shift in how digital media is produced and consumed.
Kling VIDEO 3.0 gives every user the power of a director. The ability to lock in core elements and generate 15 seconds of cinematic flow marks the beginning of a new chapter in digital media. Creators now have the freedom to tell stories that were previously impossible to produce without a large team and a massive budget. Such a launch is the first step toward a future where imagination is the only limit to cinematic creation.
The launch of the Kling VIDEO 3.0 model series marks a new era for AI video creation. Through the combination of native audio, character consistency, and cinematic shot control, the platform gives every user the power of a director. Narrative storytelling becomes more fluid as creators generate 15-second clips with precise detail and sound. These tools simplify the professional workflow, allowing for high-quality cinematic results without the need for complex editing software.
FAQs
Q1. How does Kling VIDEO 3.0 manage identity stability when multiple characters interact?
Through advanced semantic reasoning, Kling VIDEO 3.0 independently locks and maintains the visual traits of up to three or more characters simultaneously. Such a capability guarantees that every subject remains coherent despite dramatic camera movements or scene shifts.
Q2. What makes the native audio output in Kling VIDEO 3.0 professional-grade?
The system generates visuals and sound effects in a single pass, supporting five major languages and authentic regional accents. Character referencing allows for vocal consistency, as the model extracts unique voice tones to match the visual performance.
Q3. Does Kling VIDEO 3.0 allow for precise control over narrative pacing?
Yes, the platform supports flexible output durations ranging from 3 to 15 seconds. Creators can specify the length, framing, and narrative content for individual shots within a single generation, facilitating a real sense of flow and progression.
Q4. How does the model achieve accurate text rendering on moving objects?
Kling VIDEO 3.0 utilizes native-level lettering capabilities to place precise text on surfaces like signs or documents. Through improved semantic accuracy, characters and symbols remain stable and correctly oriented even during complex camera pans.
Q5. What is the benefit of combining image references with element locks?
Utilizing multiple perspective images helps the model build a 3D-like understanding of a subject. Kling VIDEO 3.0 anchors these core traits, allowing for cinematic shot-reverse-shot sequences where the character's appearance stays identical across every angle.








